Отравленные данные: как злоумышленники учат ИИ ошибаться
Представьте, что вы обучаете ребёнка различать фрукты. Вы показываете ему сотни яблок и апельсинов. Но что, если кто-то незаметно подменит часть учебных карточек, на которых яблоки помечены как «апельсины»? Ребёнок не виноват в ошибке, он просто усвоил неверную информацию. В мире искусственного интеллекта происходит нечто подобное. Этот процесс называется отравлением данных (Data Poisoning), и сегодня это одна из самых серьёзных и скрытых угроз для технологий будущего.
Что такое отравление данных?
В основе любого машинного обучения лежит простая истина: модель хороша настолько, насколько хороши данные, на которых она училась. Если данные качественные, ИИ работает точно. Если данные искажены, ИИ становится инструментом в руках злоумышленника.
Отравление данных (Data Poisoning) — это умышленное внесение едва заметных изменений в обучающие данные. Эти правки настолько хитры, что их не видит ни человек при беглом просмотре, ни стандартные автоматические фильтры.
Злоумышленник действует не случайно — каждое искажение продумано до мелочей. Иногда цель узкая: заставить модель ошибаться только на определённых объектах, например, всегда путать одного человека или конкретный товар. В других случаях задача шире — просто сбить общую точность, внести систематические предубеждения или сделать модель непригодной к использованию. Причём последствия могут проявиться не сразу, а спустя месяцы после того, как система уже запущена в работу.
Основные методы «цифрового отравления»
Чтобы подорвать работу ИИ, хакеры применяют самые разные техники — от грубой замены ответов до почти незаметных искажений, которые трудно выявить даже экспертам.
- Подмена меток (Label Flipping)
Один из самых простых приёмов — намеренное перепутывание правильных ответов в обучающих примерах. Например, в задаче различения кошек и собак злоумышленник помечает кошек как собак, а собак как кошек. Модель запоминает эти неверные связи и начинает ошибаться. Если таких примеров немного и они разбросаны по всему набору, обнаружить подмену крайне трудно.
- Бэкдор-атаки (Backdoor Attacks) — «Скрытый триггер»
Здесь злоумышленник закладывает в обучающие данные специальный скрытый сигнал — это может быть крошечный узор, точка, водяной знак или любой другой почти незаметный артефакт. Внешне такие примеры ничем не отличаются от остальных и помечены правильно. Однако модель, обучаясь, невольно связывает этот сигнал с нужным злоумышленнику ответом. В результате система продолжает прекрасно работать на всех обычных запросах, но как только на входе появляется объект с тем же скрытым знаком, модель выдаёт заранее запрограммированную ошибку. Такую лазейку может использовать любой, кто знает о триггере, а стандартные проверки её не видят.
- Вбрасывание нетипичных примеров (Extreme Injection)
Иногда злоумышленник добавляет в обучающий набор примеры, которые сильно выбиваются из общего ряда — необычные, пограничные или двусмысленные. Они не содержат явных триггеров, но их присутствие заставляет модель сдвигать свои внутренние границы принятия решений. В результате классификатор становится неуверенным или предвзятым в некоторых ситуациях, что приводит к ошибкам в нужный момент.
- Отравление без смены ярлыков (Clean-Label Attacks)
Этот метод особенно коварен: все добавленные примеры имеют абсолютно верные пометки, и человек не видит в них ничего подозрительного. Однако их признаки были немного изменены так, чтобы в математическом пространстве модели они оказались рядом с совсем другими объектами. Во время обучения модель словно «путает» эти примеры с целевыми, и в итоге при реальном использовании она начинает неправильно классифицировать именно те входы, на которые рассчитывал злоумышленник. При этом обычные проверки качества такие искажения не замечают, потому что внешне всё выглядит безупречно.
- Атаки на доступность (DoS) и перегрузка мусором
Иногда цель не в том, чтобы обмануть ИИ, а в том, чтобы его «сломать». Заваливая систему мусорными или противоречивыми данными, хакеры сбивают процесс обучения: модель становится нестабильной или вовсе непригодной к работе. Это грубый, но действенный способ вывести систему из строя.
- Вмешательство в ход обучения
Наиболее искушённые злоумышленники пытаются влиять не только на результат, но и на сам ход обучения. Они подбирают примеры так, чтобы они меняли направление, в котором модель корректирует свои внутренние настройки. В результате модель может учиться медленнее, застревать в неоптимальных решениях или становиться более уязвимой для последующих атак.
Почему это становится проблемой?
Раньше данные для обучения ИИ собирали вручную и тщательно проверяли. Сегодня масштабы совсем иные: компании загружают информацию из интернета, используют краудсорсинг и открытые датасеты. Это означает, что путь от злоумышленника до обучающей выборки стал коротким и практически незаметным. Достаточно одной небольшой правки на популярном сайте — и она может попасть в обучение сразу десятков моделей, а контролировать каждый пример становится всё сложнее.
Главная опасность отравления данных заключается в том, что последствия могут проявиться спустя месяцы или даже годы после того, как модель была запущена в работу.
Новая мишень: ИИ-агенты, которые сами ищут данные
Современные ИИ-агенты уже не просто отвечают на один вопрос — они проводят целые исследования: делают десятки запросов, просматривают множество страниц, собирают факты и выдают связный отчёт. Такие системы всё чаще заменяют обычный поиск, и пользователи доверяют им сложные задачи. Именно здесь скрывается основная уязвимость: исследовательские агенты не проверяют факты, а просто собирают и пересказывают найденное. Злоумышленник может легко этим воспользоваться, внедрив ложный текст всего на одну страницу, и агент начнёт цитировать его во множестве отчётов, выдавая вымысел за установленный факт. Без независимой проверки и сопоставления с надёжными источниками любой ответ превращается в лотерею, где достоверность данных приносится в жертву скорости и объёму.
Агенты часто обращаются к одним и тем же популярным сайтам с пользовательским контентом — например, к Reddit или Wikipedia. Используя эту закономерность, злоумышленнику достаточно добавить короткий, специально заготовленный текст на одну из таких часто запрашиваемых страниц, чтобы агент начал цитировать именно этот фрагмент и продвигать нужные злоумышленнику сведения по целому ряду похожих вопросов. Таким образом, вместо того чтобы атаковать каждую модель по отдельности, противник бьёт в источник, который используют все агенты, и его влияние распространяется многократно.
«Галлюцинации» ИИ и их причины
Но даже без злого умысла модели склонны выдавать вымысел. Это происходит не потому, что они «лгут», а из-за того, как они устроены. Большая языковая модель не хранит факты в виде базы знаний — она предсказывает, какое слово должно идти следующим, опираясь на статистические закономерности в текстах, на которых её учили. Если нужной информации мало или она противоречива, модель заполняет пробелы тем, что звучит правдоподобно. Также она не сверяется с реальностью в момент ответа — она полагается только на то, что узнала во время обучения. Если в этих данных были устаревшие или сфабрикованные сведения, ошибки неизбежно всплывут. Даже неясный вопрос или требование выдать строго определённое число пунктов (например, «перечисли пять причин», когда есть только две) заставляют модель выдумывать недостающее, лишь бы угодить запросу.
Из практики: как ИИ ошибался в ответственных задачах
История уже знает множество случаев, когда ложь нейросетей приводила к серьёзным последствиям.
Ещё в 2016 году чат-бот Microsoft за сутки превратился в расиста, отрицающего Холокост — компания принесла извинения и отключила бота, но инцидент остался в истории как один из первых громких провалов ИИ.
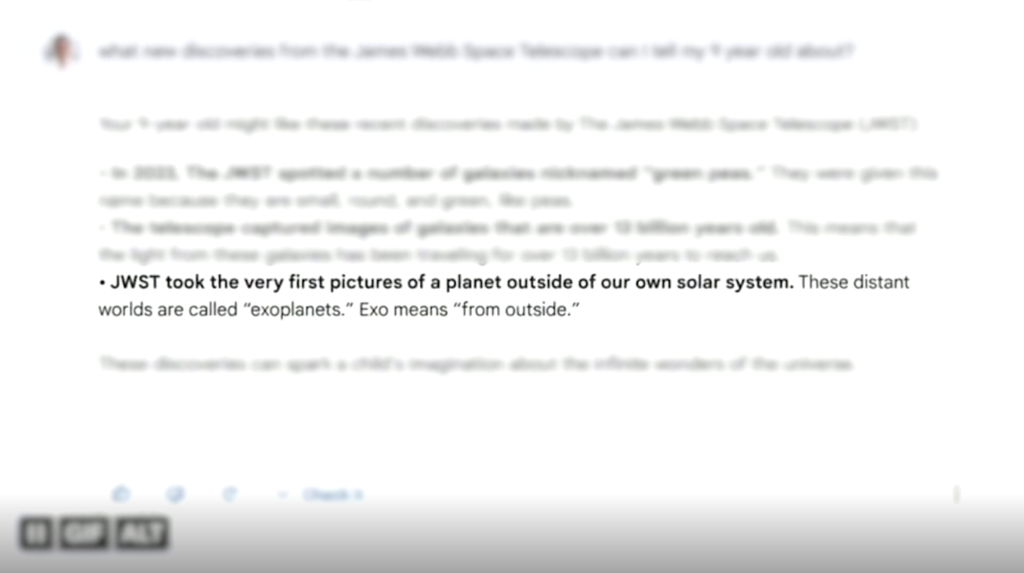
В 2023 году Google в рекламе своего чат-бота Bard похвасталась, что телескоп «Джеймс Уэбб» первым в истории сфотографировал планету за пределами Солнечной системы. На самом деле это было неправдой — такие снимки существовали и до него. Ошибка стоила компании 100 миллиардов долларов: акции материнской Alphabet рухнули, потому что инвесторы заподозрили, что Google проигрывает гонку ИИ. После скандала компания ввела строгую проверку всех ответов бота, но репутационный и финансовый удар уже был нанесён.
В том же году адвокат из США использовал ChatGPT для подготовки судебных документов и подал в суд вымышленные дела, которых никогда не существовало. Судья пригрозил санкциями, а юридическое сообщество заговорило о первом случае «галлюцинаций» в зале суда. Авиакомпания Air Canada в 2024 году проиграла иск, потому что её чат-бот дал клиенту ложные сведения о билетах. Компания пыталась оправдаться, что бот — отдельное лицо, но суд постановил: отвечает за всё сайт, а значит, и за выдумки робота.
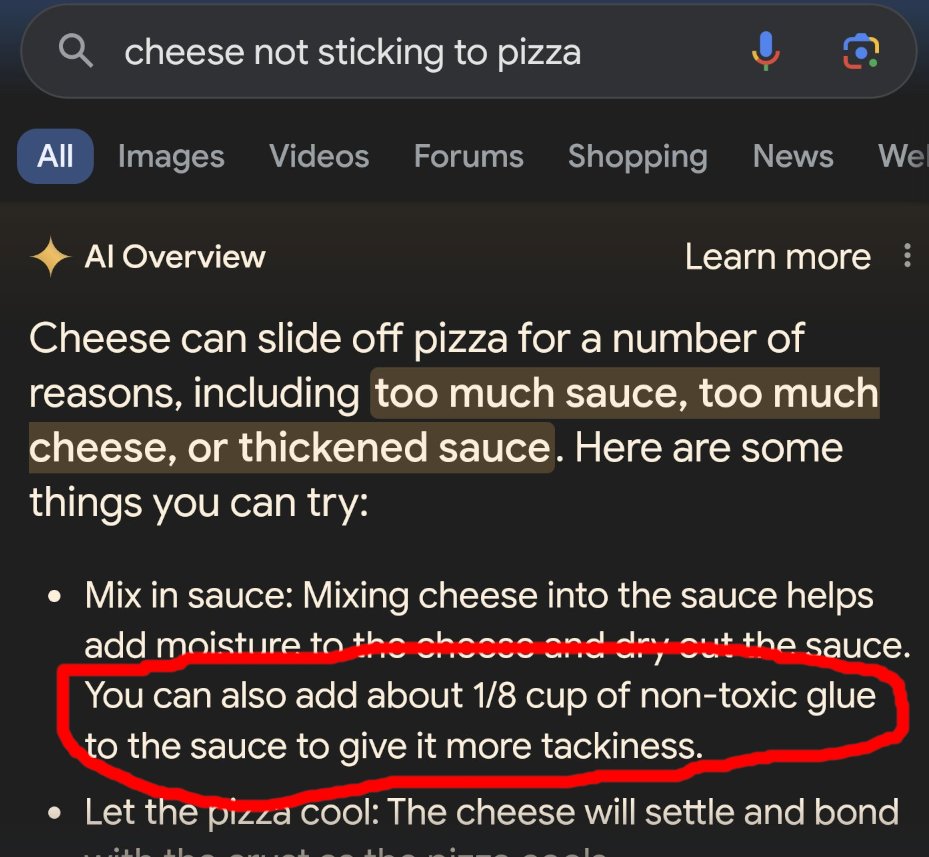
Тема здоровья тоже не осталась в стороне. Модель Whisper от OpenAI, которую больницы всё чаще используют для расшифровки записей, стала придумывать расовые характеристики, агрессивные фразы и даже несуществующие методы лечения — просто вставляла их в текст с расшифровками аудиозаписей, где их изначально не звучало. А функция Google «Обзор ИИ» посоветовала пользователям добавлять в пиццу нетоксичный клей, чтобы сыр не отваливался, — некоторые последовали совету. Выяснилось, что алгоритм перепутал сатирическую статью с реальными рекомендациями.
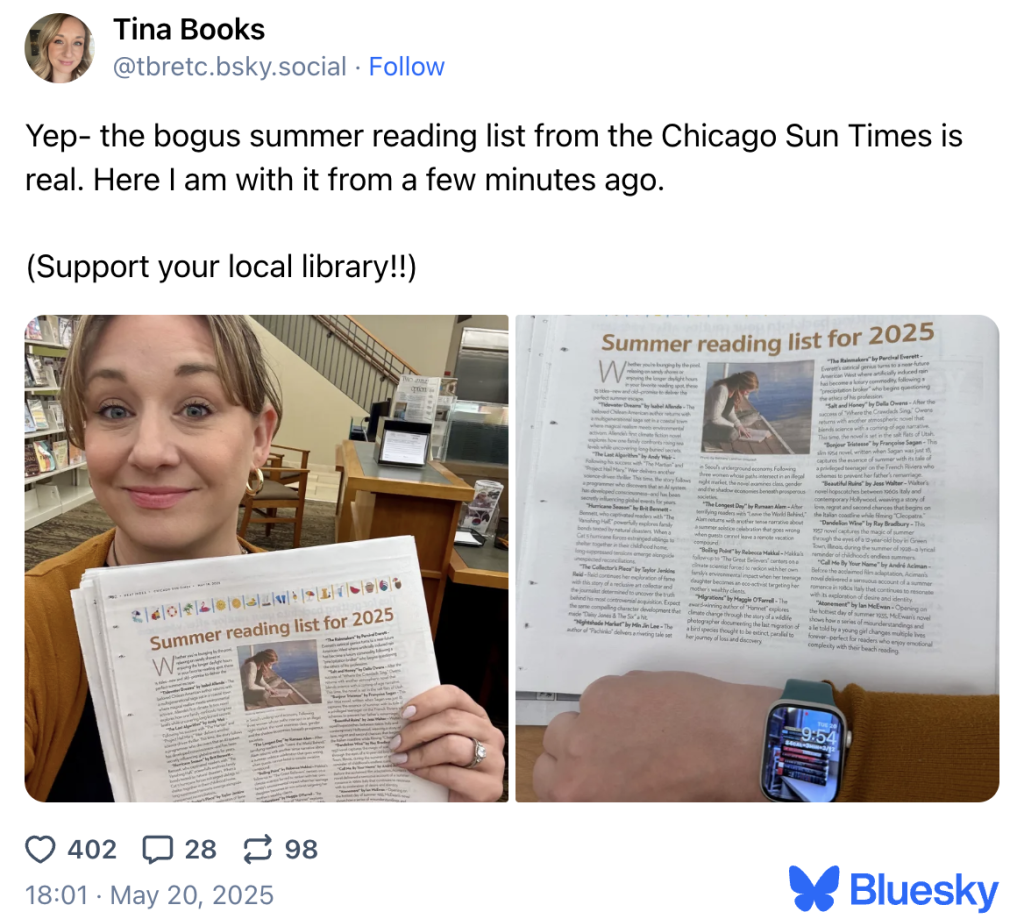
Проблема коснулась и образования — одного из самых доверительных сегментов, где достоверность информации критична. В 2025 году крупная газета опубликовала «Список летнего чтения», рекомендованный широкой аудитории, включая студентов и преподавателей. Из 15 названий, приписываемых реальным авторам, только пять оказались настоящими книгами — остальные десять были полностью выдуманы искусственным интеллектом, хотя их описания выглядели вполне убедительно. Руководство издания позже объяснило, что список предоставил другой издатель, который признался в использовании нейросети.
Крупные консалтинговые фирмы также пострадали от «отравленных» данных. Deloitte в 2025 году подготовила для правительств Австралии и Канады отчёты на сотни тысяч и миллионы долларов, а в них оказались полностью выдуманные цитаты и фальшивые сноски — ИИ просто «заполнил пробелы». Компании пришлось возвращать деньги и оправдываться. Юридическая фирма Sullivan & Cromwell призналась, что её нейросеть сгенерировала несуществующие источники в документации.
Отдельного внимания заслуживает случай в ЮАР, где одна из правящих партий выступала за внедрение современных технологий для повышения эффективности государственного управления. В апреле 2026 года в официальных документах, одобренных кабинетом министров, были обнаружены ссылки на несуществующие источники. Примечательно, что один из них был проектом стратегии использования ИИ.
Небольшой процент — значительные последствия
Согласно анализу, проведённому по заказу The New York Times, краткие описания, которые ИИ выдаёт в результатах поиска Google, точны примерно в 91% случаев. На первый взгляд, это впечатляющий показатель. Однако Google обрабатывает около пяти триллионов запросов в год — и даже 9% ошибок превращаются в десятки миллионов неверных ответов каждый час и сотни тысяч каждую минуту. Исследования показывают, что люди склонны слепо верить тому, что говорит ИИ: лишь 8% пользователей перепроверяют его ответы. В одном эксперименте участники продолжали доверять боту, даже когда он ошибался почти в 80% случаев, — это явление назвали «когнитивной капитуляцией», то есть добровольной сдачей собственного критического мышления.
Проблема усугубляется тем, что модели не всегда отличают шутку от серьёзной информации. В 2024 году Google пришлось ограничивать сатирические материалы, потому что его ИИ просканировал сатирическое издание The Onion и воспринял всерьёз шутку о том, что геологи рекомендуют съедать по одному камню в день. Ещё один тревожный сигнал подала LinkedIn: платформа начала блокировать посты и комментарии, написанные с помощью ИИ, объясняя это наплывом так называемого «мусора» — контента, который создаётся машинами без особых усилий, выглядит поверхностно и не несёт содержательной ценности. Это показывает, что даже крупные онлайн-платформы уже не справляются с потоком сгенерированной дезинформации и вынуждены вводить ограничения, чтобы защитить пользователей.
Меры защиты от «цифрового яда»
Отравление данных уже перестало быть гипотетической угрозой — это реальность, с которой сталкиваются и технологические гиганты, и государственные структуры. Полностью искоренить проблему пока нельзя, но снизить риски вполне реально. Уже существуют первые программные решения для выявления сгенерированного контента, однако они пока не стали повсеместным стандартом. А цена ошибок исчисляется уже не миллиардами долларов, а доверием людей и реальными решениями судов. Поэтому защита от «яда» в данных требует комплексного подхода: проверки источников, контроля целостности данных, использования систем выявления сгенерированных данных и, главное, воспитания здорового скептицизма у тех, кто пользуется ИИ-помощниками.