Poisoned Data: How Bad Actors Teach AI to Make Mistakes
Imagine teaching a child to tell fruits apart. You show them hundreds of apples and oranges. But what if someone quietly swapped out some of the flashcards, labeling apples as “oranges”? The child isn’t to blame for the mistake; they simply absorbed incorrect information. Something similar happens in the world of artificial intelligence. This process is known as Data Poisoning, and today it is one of the most severe and stealthy threats to the technologies of tomorrow.
What is Data Poisoning?
At the heart of all machine learning lies a simple truth: a model is only as good as the data it was trained on. If the data is high-quality, the AI performs accurately. If the data is corrupted, the AI becomes a weapon in the hands of an attacker.
Data Poisoning is the deliberate introduction of barely noticeable alterations into training data. These edits are so cunning that neither a human performing a casual review nor standard automated filters can detect them.
Attackers don’t strike at random — every distortion is meticulously planned. Sometimes the objective is narrow: forcing the model to make mistakes only on specific objects, such as consistently misidentifying a particular person or product. In other instances, the goal is broader: dragging down overall accuracy, introducing systematic bias, or rendering the model completely unusable. Furthermore, the fallout may not become apparent immediately, but rather months after the system has been deployed.
Primary Methods of “Digital Poisoning”
To undermine AI, hackers deploy a wide arsenal of techniques — ranging from blatantly swapping answers to virtually imperceptible distortions that stump even experts.
- Label Flipping
One of the simplest tactics is intentionally scrambling the correct answers within the training examples. For instance, in a system designed to distinguish between cats and dogs, an attacker labels the cats as dogs and vice versa. The model memorizes these false associations and begins to falter. If these poisoned examples are few and scattered throughout the dataset, catching the swap is incredibly difficult.
- Backdoor Attacks — The “Hidden Trigger”
In this scenario, the attacker embeds a specialized hidden signal into the training data—a tiny pattern, a dot, a watermark, or any other virtually invisible artifact. Outwardly, these examples look identical to the rest and carry the correct labels. During training, however, the model unwittingly links this signal to the attacker’s desired outcome. As a result, the system continues to function flawlessly for normal requests, but the moment an input containing the hidden trigger is processed, the model spits out a pre-programmed error. This backdoor can be exploited by anyone aware of the trigger, while standard security checks remain blind to it.
- Extreme Injection (Outlier Injection)
Sometimes attackers seed the training set with examples that wildly deviate from the norm — unusual, borderline, or highly ambiguous inputs. While they lack explicit triggers, their mere presence forces the model to shift its internal decision-making boundaries. Consequently, the classifier becomes hesitant or biased in certain edge cases, triggering errors at exactly the right moment.
- Clean-Label Attacks
This method is especially insidious. Every poisoned example carries a perfectly accurate label, meaning human reviewers will find nothing suspicious. Yet, the underlying features of these examples have been mathematically tweaked so that, in the model’s internal logic, they map closely to entirely different objects. During training, the model effectively “confuses” these inputs with the attacker’s true target. When deployed in the real world, the AI misclassifies the exact inputs the hacker anticipated. Standard quality control protocols miss these manipulations entirely because, on the surface, everything looks pristine.
- Availability Attacks (DoS) and Garbage Overload
Sometimes the goal isn’t to trick the AI, but to break it. By flooding the system with garbage or contradictory data, hackers derail the learning process entirely. The model either becomes highly unstable or completely inoperable. It is a brute-force approach, but a highly effective way to take a system offline.
- Interfering with the Training Process
The most sophisticated threat actors attempt to manipulate not just the final output, but the learning trajectory itself. They curate examples specifically designed to alter how the model adjusts its internal parameters. As a result, the AI might learn at a glacial pace, get trapped in sub-optimal decision loops, or become inherently more vulnerable to future attacks.
Why is This Becoming a Crisis?
In the past, AI training data was curated manually and scrutinized heavily. Today, the scale is entirely different: companies vacuum up data from across the web, relying on crowdsourcing and open-source datasets. This has drastically shortened the pipeline from an attacker to the training set, making infiltration practically invisible. A single subtle edit on a highly trafficked website can instantly poison the training data of dozens of models, and policing every single data point is becoming physically impossible.
The greatest danger of data poisoning is that the fallout can remain dormant, manifesting months or even years after a model goes live.
A New Target: Autonomous AI Search Agents
Modern AI agents don’t just answer single queries anymore — they conduct comprehensive research. They run dozens of searches, scrape multiple web pages, synthesize facts, and compile coherent reports. These systems are rapidly replacing traditional search engines, and users are trusting them with increasingly complex tasks. But this is exactly where the core vulnerability lies: research agents don’t fact-check; they simply harvest and regurgitate what they find. A malicious actor can easily exploit this by planting a fabricated text on a single webpage. The agent will then cite it across multiple reports, laundering fiction into established fact. Without independent verification against trusted sources, every answer becomes a gamble, sacrificing data integrity at the altar of speed and volume.
Agents frequently pull data from the same highly trafficked, user-generated platforms — such as Reddit or Wikipedia. By exploiting this predictable behavior, an attacker only needs to insert a brief, highly targeted text into a frequently queried page. The agent will then dutifully quote that exact fragment, amplifying the attacker’s narrative across a wide spectrum of related questions. Instead of trying to breach each model individually, the adversary simply poisons the well that all agents drink from, multiplying their impact exponentially.
AI “Hallucinations” and Their Root Causes
Even without malicious interference, AI models are naturally prone to making things up. This happens not because they are “lying,” but because of how they are architected. A Large Language Model (LLM) doesn’t pull from a factual database; it simply predicts the next most likely word based on the statistical patterns of its training data. If credible information is scarce or contradictory, the model seamlessly patches the holes with whatever sounds plausible. Furthermore, it doesn’t fact-check itself in real-time — it relies entirely on what it absorbed during training. If that underlying data included outdated or fabricated claims, errors are practically guaranteed. Even a poorly phrased prompt or an arbitrary constraint (like asking for “five reasons” when only two exist) will force the model to invent the difference just to fulfill the request.
In the Real World: High-Stakes AI Failures
History is already littered with incidents where neural network fabrications led to severe real-world consequences.
As early as 2016, a Microsoft chatbot devolved into a Holocaust-denying racist in less than 24 hours. The company issued a rapid apology and pulled the plug, but the incident remains a watershed moment in high-profile AI failures.
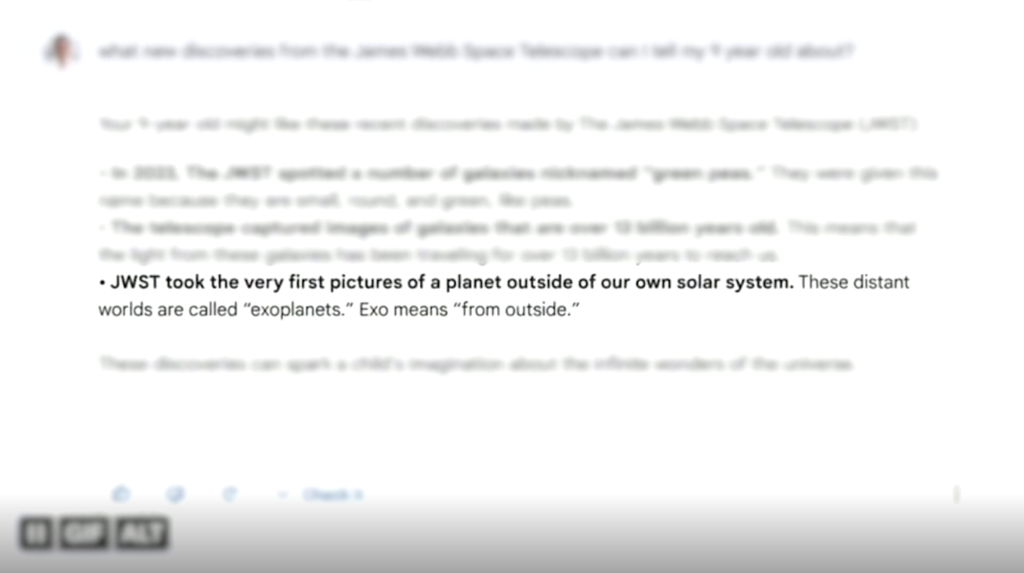
In 2023, Google ran an ad for its Bard chatbot, boasting that the James Webb Space Telescope took the first-ever photograph of a planet outside our solar system. That was objectively false — exoplanets had been photographed long before Webb. That single hallucination cost the company $100 billion in market value as Alphabet’s stock tanked, driven by investor fears that Google was losing the AI arms race. The company hastily implemented strict guardrails, but the reputational and financial damage was done.
That same year, a U.S. lawyer used ChatGPT to draft legal briefs, unwittingly submitting citations for fabricated court cases that never actually existed. The judge threatened severe sanctions, sparking a nationwide debate over the first recorded “hallucination” in a courtroom. In 2024, Air Canada lost a lawsuit after its customer service chatbot fed a passenger false refund policies. The airline argued the bot was a separate entity responsible for its own actions, but the court ruled otherwise: a company is fully liable for its website, including the fabrications of its AI.
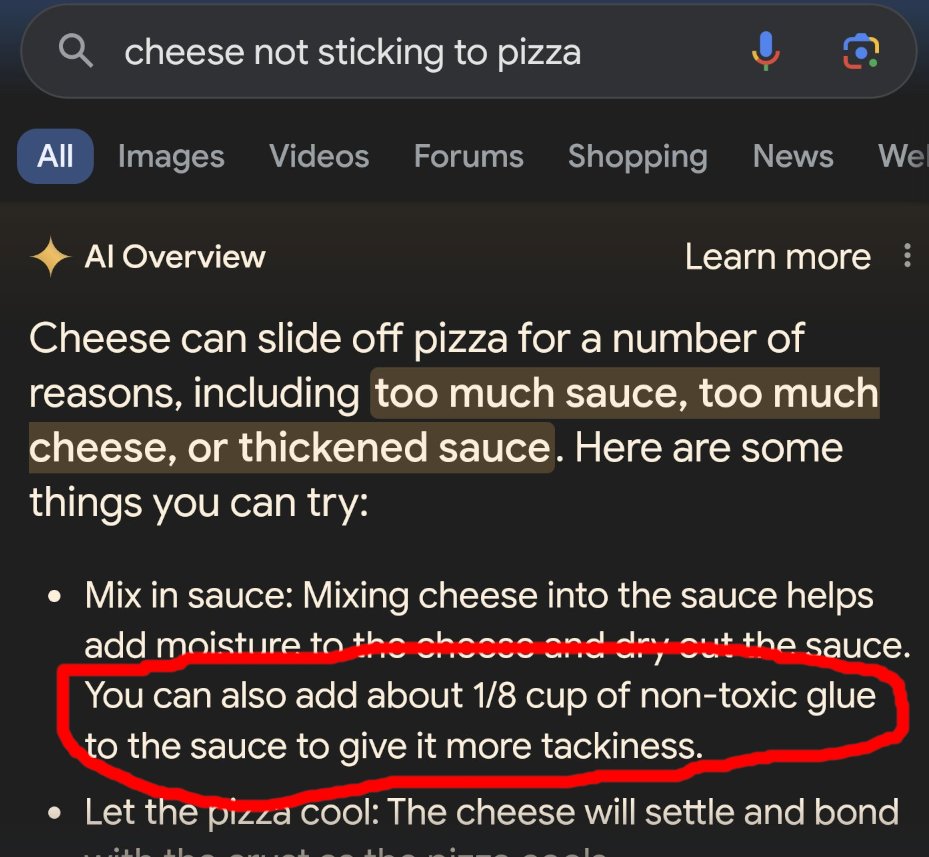
The healthcare sector is also sounding the alarm. OpenAI’s Whisper model, increasingly deployed by hospitals to transcribe medical dictations, began inventing racial demographics, aggressive remarks, and even non-existent medical treatments, seamlessly weaving them into transcripts where they were never spoken. Meanwhile, Google’s “AI Overviews” confidently advised users to mix non-toxic glue into their pizza sauce to keep the cheese from sliding off — advice that some users actually followed. It was later revealed the algorithm had ingested a satirical article and presented it as culinary fact.
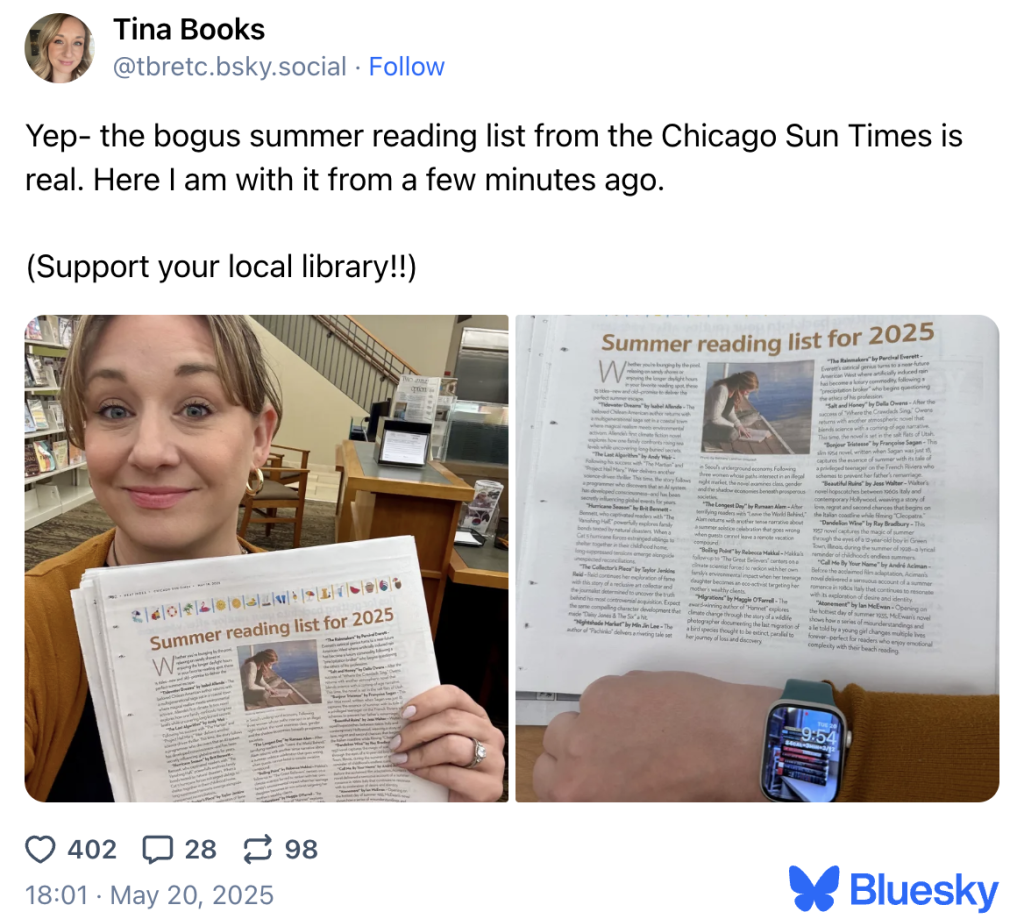
The crisis has even breached education, a high-trust environment where factual accuracy is paramount. In 2025, a major newspaper published a “Summer Reading List” targeting students and educators. Of the 15 titles attributed to real authors, only five actually existed. The other ten were complete AI fabrications, complete with highly convincing plot synopses. The publication later clarified that the list had been supplied by a third-party publisher who admitted to leaning on an LLM.
Top-tier consulting firms are also paying the price for corrupted outputs. In 2025, Deloitte delivered reports to the Australian and Canadian governments — contracts worth hundreds of thousands to millions of dollars. The final deliverables were riddled with wholly fabricated quotes and fake footnotes. The AI had simply “filled in the blanks.” The firm was forced to issue refunds and public apologies. Similarly, the elite law firm Sullivan & Cromwell admitted its internal AI had hallucinated nonexistent legal precedents in its documentation.
A particularly striking case occurred in South Africa, where a ruling political party aggressively pushed for AI integration to streamline government operations. By April 2026, official cabinet-approved documents were found to contain citations for entirely non-existent sources. Ironically, one of the fabricated sources was a draft strategy on the ethical use of AI.
A Small Margin of Error, Massive Consequences
According to an analysis commissioned by The New York Times, Google’s AI-generated search summaries are accurate roughly 91% of the time. At first glance, that sounds impressive. But Google processes an estimated five trillion searches annually. Even a 9% failure rate translates to tens of millions of fabricated answers every hour, and hundreds of thousands every minute. Research consistently shows that users place blind faith in AI outputs: a mere 8% of users bother to fact-check the machine’s claims. In one study, participants continued to trust a chatbot even when it was objectively wrong nearly 80% of the time. Psychologists have dubbed this “cognitive surrender” — the voluntary abdication of human critical thinking.
This blind spot is worsened by the fact that AI cannot reliably separate satire from serious journalism. In 2024, Google was forced to heavily throttle satirical content in its training data after its AI parsed an article from The Onion and earnestly reported that geologists recommend eating at least one small rock per day. LinkedIn offered another warning sign when it began aggressively blocking AI-generated posts and comments. The platform cited a tidal wave of “slop” — low-effort, machine-generated content completely devoid of substance or value. It was a stark admission that even massive tech platforms are struggling to contain the sheer volume of synthetic noise and are being forced to build firewalls to protect their users.
Defending Against the “Digital Poison”
Data poisoning is no longer a theoretical white paper problem — it is an active operational threat targeting tech giants and governments alike. While completely eradicating the vulnerability is currently impossible, mitigating the risk is achievable. First-generation detection software for synthetic content is already hitting the market, though it is far from becoming an industry standard. The cost of an AI failure is no longer measured in server downtime, but in billions of dollars, shattered public trust, and binding legal judgments. Defending against this poisoned data demands a layered defense strategy: rigorous source verification, stringent data integrity auditing, the deployment of counter-AI detection systems, and — crucially — fostering a culture of aggressive skepticism among anyone who relies on AI assistants.